Geschreven door Matthias van den Berg
The Cribl product and their certifications
In this blog I would like to talk about Cribl and what its possibilities are and what their certification track currently looks like.
After seeing a demo of the possibilities of Cribl I wanted to learn more about the product and how we could use it. I have been a Splunk administrator for a few years now and while following the demo I could see how Cribl solves some of the issues and struggles I face as a Splunk administrator.
Cribl
Cribl positions itself as a layer between your data sources and your data analytics tools like Splunk, Elastic, Databricks & more.
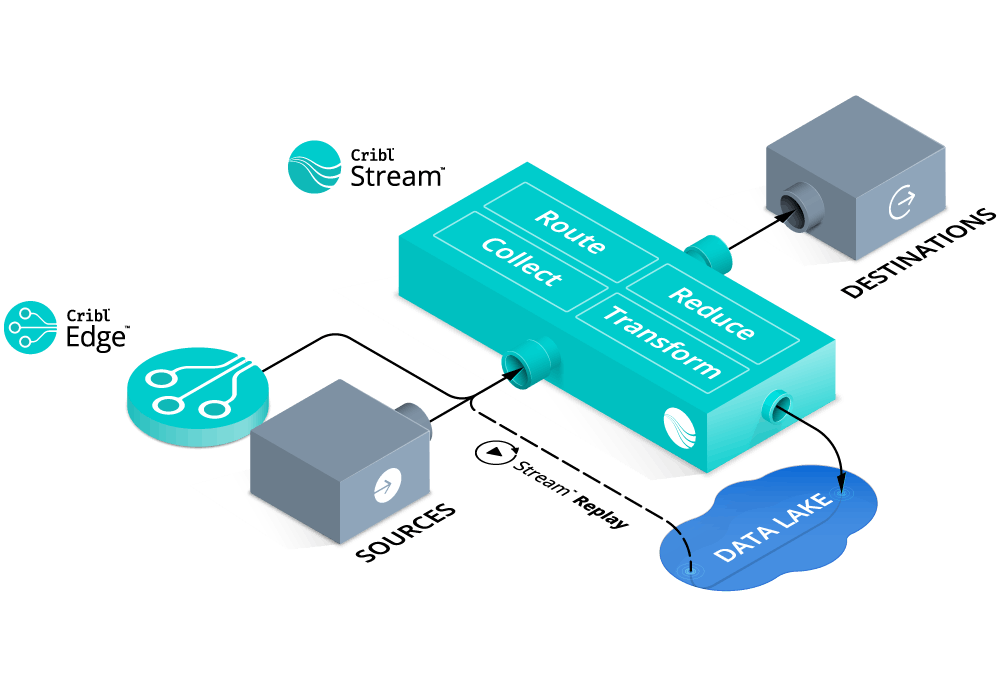
They call this layer: Cribl Stream. It can receive data and then change, transform and reduce the data before sending it off to different destinations. Below are a few of the options that Stream offers:
- Change the data format of the data going out, for example you could change it to JSON.
- Drop all the empty/null value fields in the data.
- Sent a portion of the event to your SIEM and store the raw log event into a S3 bucket as an archive.
- Replay that archive S3 bucket to load the full events into your SIEM when you need to investigate/troubleshoot an issue.
- Mask sensitive information for 1 destination but send all data to a 2nd data analytics tool.
- Receive data from existing agents as the Splunk forwarder or Elastic Beats.
All of these options are available in a GUI and you can see the effects of changes you are making before actually applying them. After learning about the possibilities I decided it was worth to do a proof of concept in my local test environment.
Proof of concept
The goal of the proof of concept was to see how I could send data from a network appliance, and get it into Splunk in a JSON format while also reducing the noise in the events.
There are several options for installing Stream. You can install it on your local machine, use Docker containers or you can make use of their free cloud environment to test things. I installed Stream on a Linux virtual machine and after a few minutes it was already up and running.
The first thing I needed to do was to send data to Stream. Since it is able to receive syslog data, I logged into my router/firewall and started to send my network traffic information to Stream using syslog. In the Stream GUI I started to look at the data coming in, there were a few fields to remove and I wanted to rename some of the other fields.
After a few minutes I had prepared the changes and could see what would happen if I pushed the change out. The data was almost ready, I only needed to change the format to JSON and add an index and sourcetype field since I was going to send the data to my local Splunk HEC endpoint.
All in all the entire POC cost about an hour to do and I was really happy with the results.
Cribl edge
Besides Stream they also offer the edge software, which is an agent you can install on Linux or Windows servers. The main point of the agent is that it can be used to discover data and also route the data to different types of receivers like, Splunk, Elastic or Databricks. This could help to reduce the amount of agents needed on endpoints and have 1 agent to get the data from your endpoints.
Certification tracks
To learn more about Stream, I went to https://cribl.io/university/ and saw that they offer the certification tracks for free. Currently there are two certifications that you can acquire:
For anyone wanting to learn more about Stream, I highly recommend to start with Stream User. It is a combination of video’s, questions and their own sandbox environment which lets you make the changes in the actual product. You really get a good sense of the possibilities of Stream and how you should use the product.
After finishing the Stream User I went along and followed the Stream Admin track, they really go in depth and help you understand what is happening inside of Stream. If you are thinking about doing a Proof of concept in an enterprise environment this will really help you understand how to set it up.
I hope this blog gives a feel of what Cribl is and does, and if you have any questions please feel free to reach out to me on LinkedIn.
Geschreven door CINQ